Step-by-Step Guide for Integrating ProxyJet Proxies in Scrapy
What is Scrapy?
Scrapy is a powerful web crawling and scraping framework for Python. It enables developers to extract data from websites and process it as needed. Integrating proxies into Scrapy helps bypass IP bans, access geo-restricted content, and maintain anonymity during scraping tasks.
Use Case for ProxyJet Integration:
Integrating ProxyJet with Scrapy allows users to leverage high-quality residential and ISP proxies, enhancing online anonymity, avoiding detection, and efficiently managing scraping tasks.
Generating Proxy in ProxyJet Dashboard
- Sign Up: Go to ProxyJet and click on "Sign Up" or "Sign Up with Google".
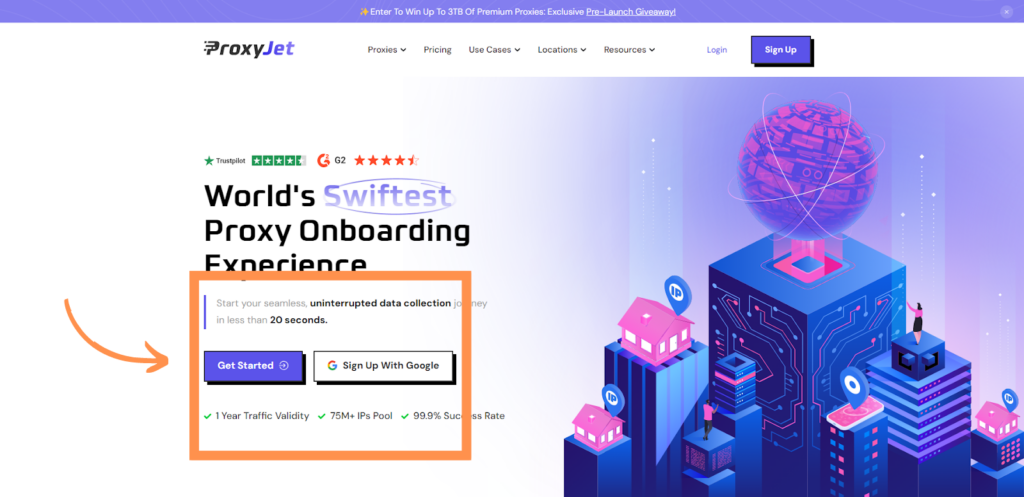
2. Create Account: If you don't use Google sign-up, please make sure you verify your email.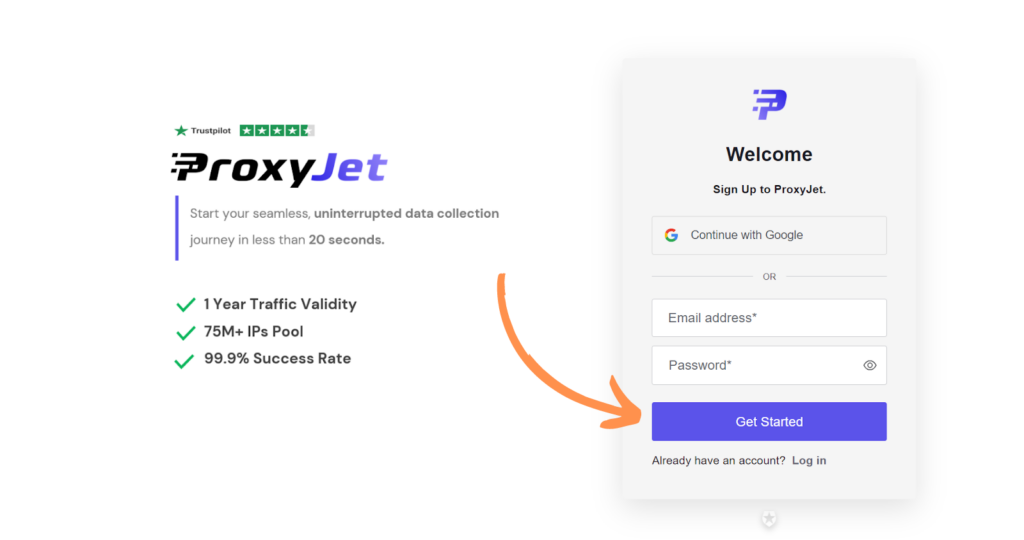
3. Complete Profile: Fill in your profile details.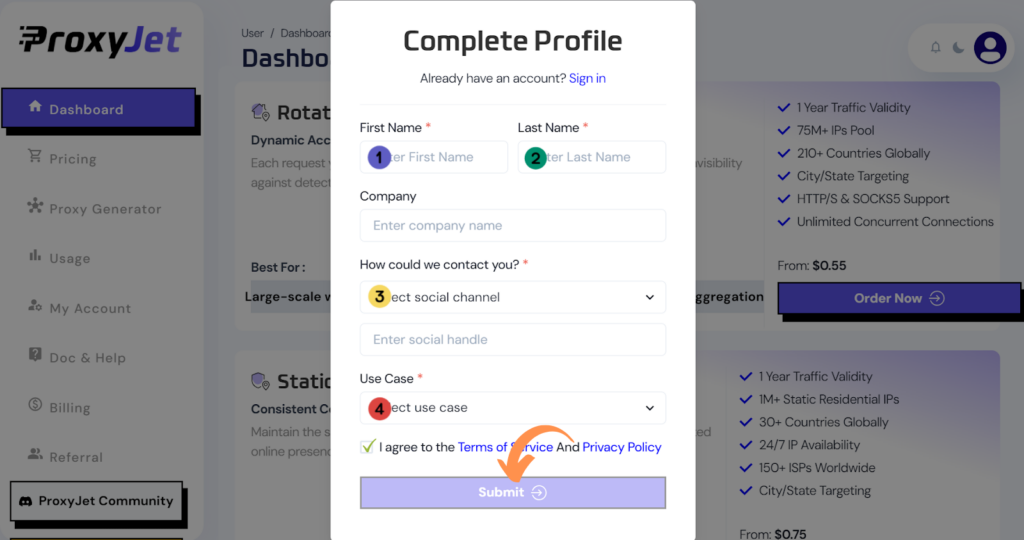
4. Pick a Proxy Type: Choose the type of proxy you need and click "Order Now".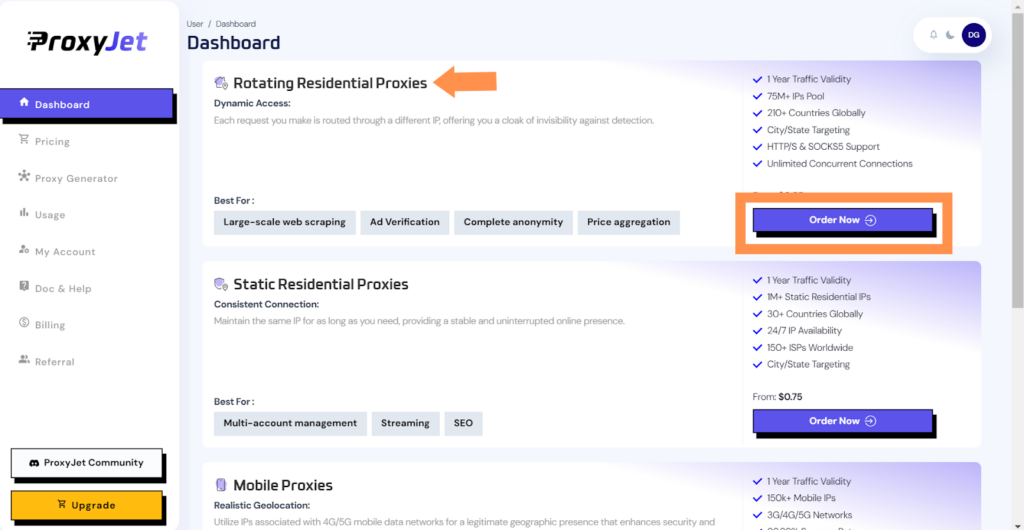
5. Pick Your Bandwidth: Select the bandwidth you need and click "Buy".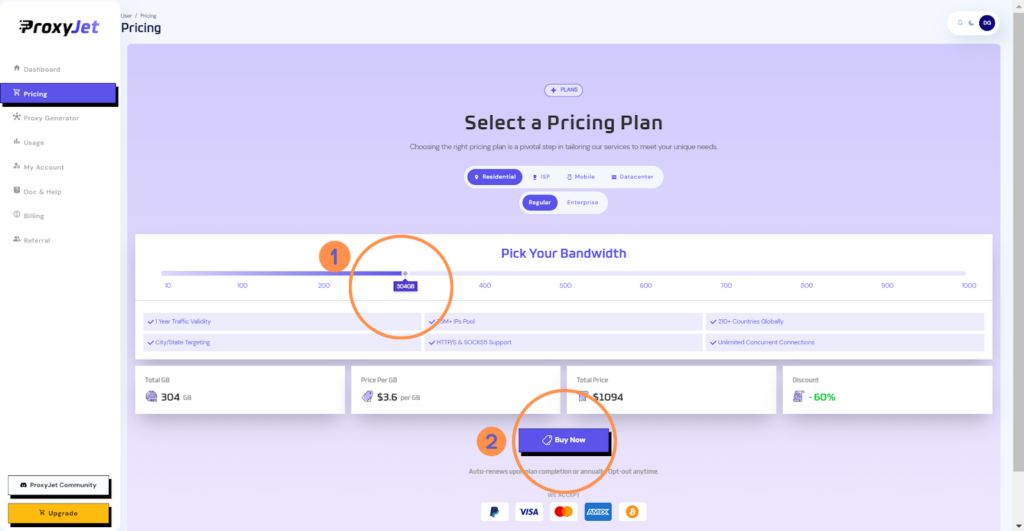
6. Complete the Payment: Proceed with the payment process.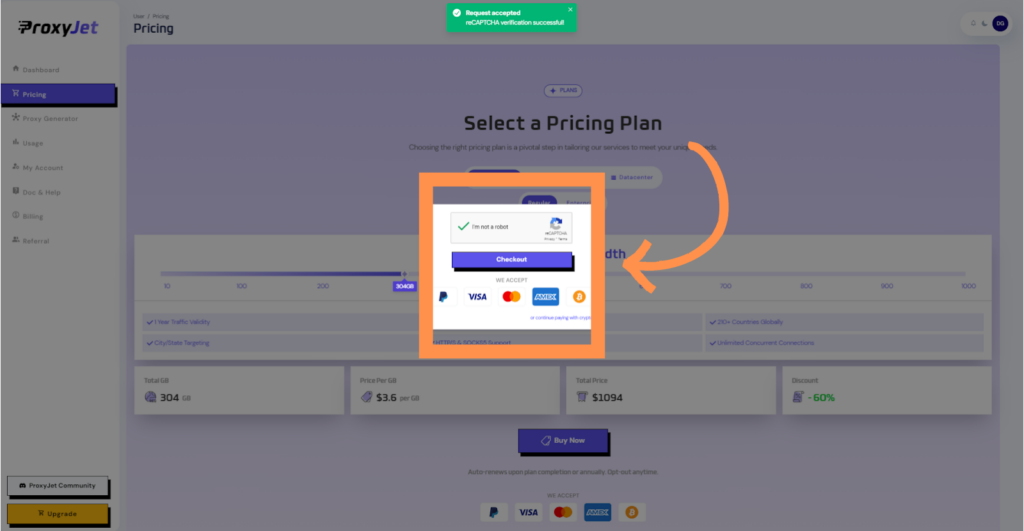
7. Access the Dashboard: After payment, you will be redirected to the main dashboard where you will see your active plan. Click on "Proxy Generator".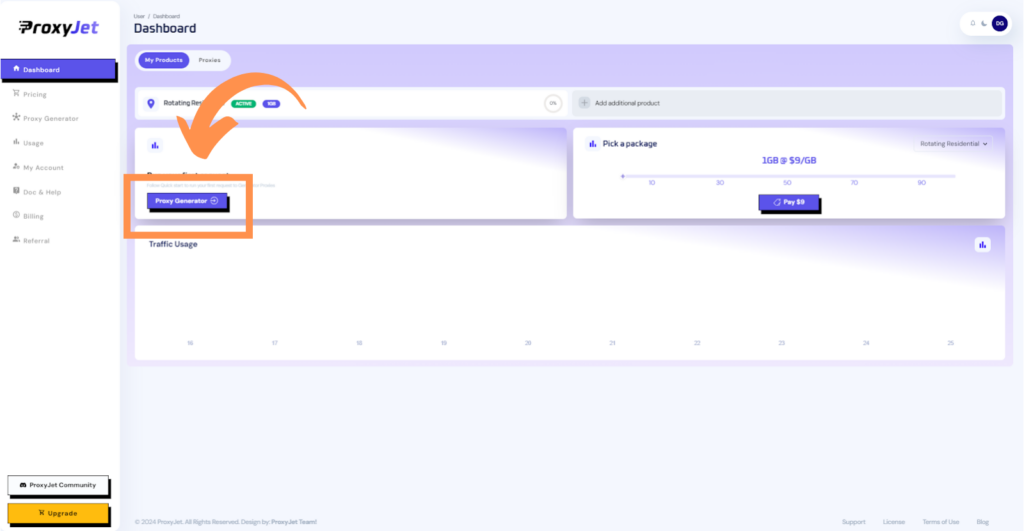
8. Switch Proxy Format: Click the toggle on the right top side of the screen that switches the proxy format to Username:Password@IP:Port.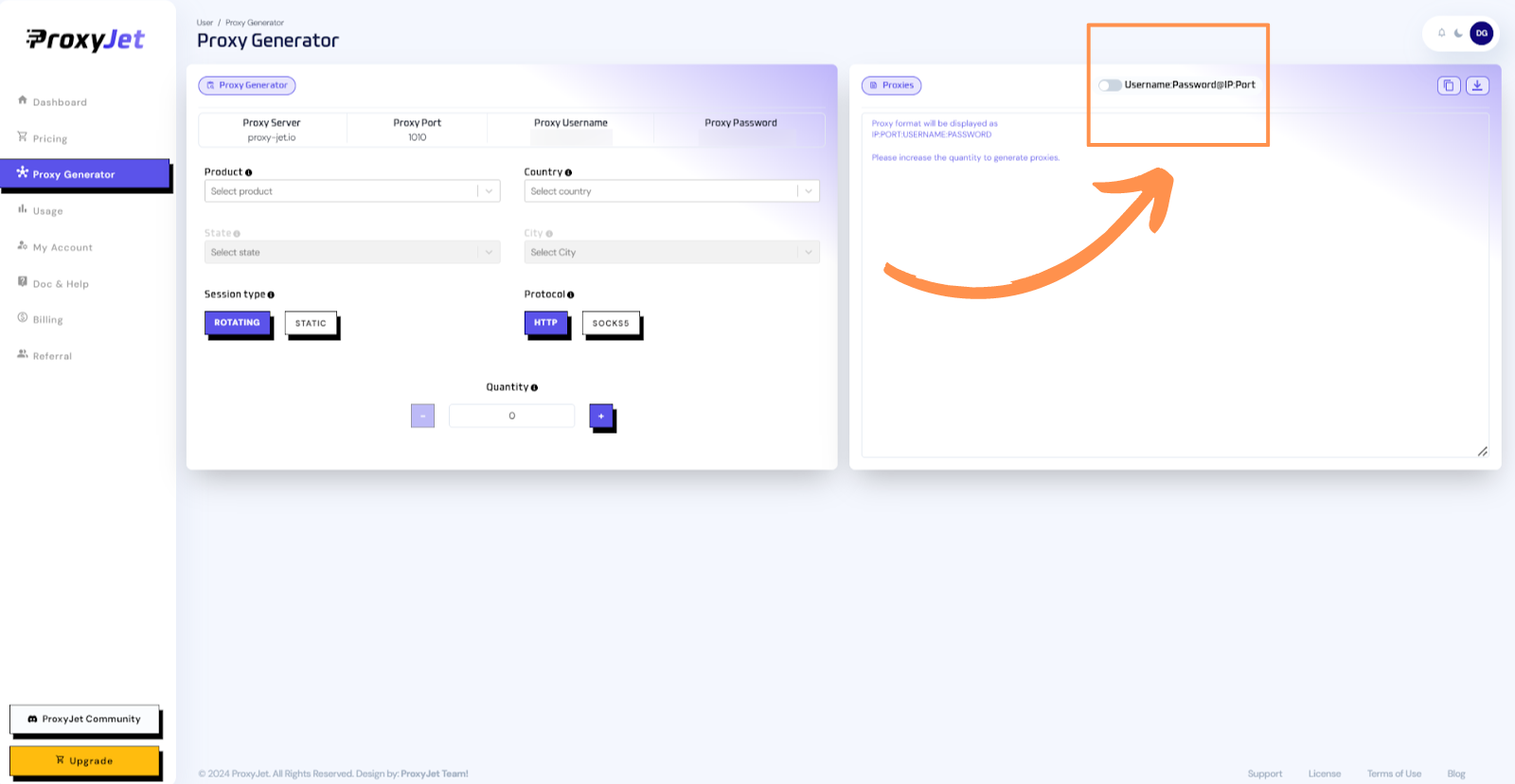
9. Generate Proxy String: Select the proxy properties you need and click on the "+" button to generate the proxy string. You will get a string that looks something like this:
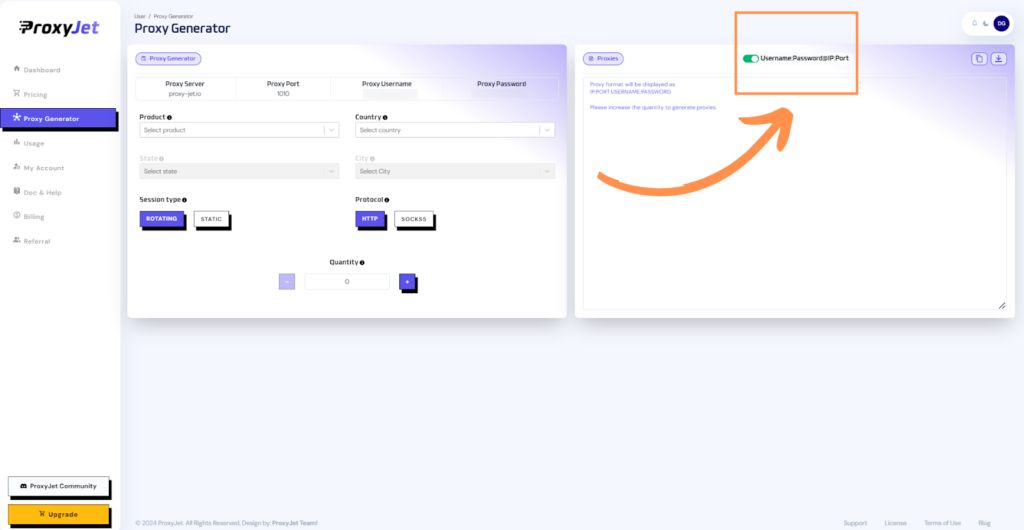
10. Great Job!: You have successfully generated your proxy!
Setting Up ProxyJet Proxies in Scrapy
Step 1: Configure Proxy in Scrapy
- Install Scrapy: Ensure you have Scrapy installed. If not, install it using pip:

- Create a Scrapy Project: Create a new Scrapy project if you haven't already:

- Modify Spider: Open your spider file and configure it to use ProxyJet proxies.
Method 1: Using Proxies as Request Parameters
You can pass the proxy details directly in the meta parameter of each scrapy.Request:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['http://example.com']
def start_requests(self): for url in self.start_urls: yield scrapy.Request( url=url, callback=self.parse, meta={"proxy": "http://A1B2C3D4E5-resi_region-US_Arizona_Phoenix:F6G7H8I9J0@proxy-jet.io:1010"} ) def parse(self, response): self.log(f'Title: {response.css("title::text").get()}')
Method 2: Creating Custom Proxy Middleware
- Create Middleware File: Create a file named
middlewares.pyin your Scrapy project and add the following code:
from w3lib.http import basic_auth_header
class ProxyMiddleware:
def init(self, proxy_url, proxy_user, proxy_pass):
self.proxy_url = proxy_url
self.proxy_user = proxy_user
self.proxy_pass = proxy_pass
@classmethod def from_crawler(cls, crawler): settings = crawler.settings return cls( proxy_url=settings.get('PROXY_URL'), proxy_user=settings.get('PROXY_USER'), proxy_pass=settings.get('PROXY_PASSWORD') ) def process_request(self, request, spider): proxy = f"http://{self.proxy_user}:{self.proxy_pass}@{self.proxy_url}" request.meta['proxy'] = proxy request.headers['Proxy-Authorization'] = basic_auth_header(self.proxy_user, self.proxy_pass)
- Configure Middleware in
settings.py:
settings.py
PROXY_URL = 'proxy-jet.io'
PROXY_USER = 'A1B2C3D4E5-resi_region-US_Arizona_Phoenix'
PROXY_PASSWORD = 'F6G7H8I9J0'
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.ProxyMiddleware': 350,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 400,
}
- Enable Middleware: Ensure that the custom middleware is enabled in your settings.
Conclusion
By following these steps, you can integrate ProxyJet proxies with Scrapy to enhance your web scraping capabilities. This setup ensures that your requests are routed securely through ProxyJet’s high-quality proxies, making your data extraction tasks more reliable and less prone to blocking.
Related Articles
Step-by-Step Guide On How To Build a Web Scraper with ProxyJet
What is a Web Scraper? A web scraper is a software tool that automates the process of extracting data from websites. It systematically browses web pages, collects the desired information, and saves it for analysis or other uses. Web scrapers are ...Step-by-Step Guide for Integrating ProxyJet Proxies in Multilogin
What is Multilogin? Multilogin is an advanced browser management tool designed to help users manage multiple online identities and accounts securely. It allows the creation of distinct browser profiles, each with unique cookies, browser fingerprints, ...Step-by-Step Guide for Integrating ProxyJet Proxies in Firefox
What is Firefox? Firefox is a widely-used web browser that prioritizes privacy, security, and customization. It supports a variety of extensions and configurations, making it an excellent choice for users who want to tailor their browsing experience. ...Step-by-Step Guide for Integrating ProxyJet Proxies in Safari
What is Safari? Safari is Apple's web browser, known for its speed, efficiency, and strong privacy features. Optimized for macOS and iOS devices, Safari offers a seamless browsing experience with advanced privacy protections like Intelligent Tracking ...Step-by-Step Guide for Integrating ProxyJet Proxies in Apify
What is Apify? Apify is a versatile web scraping and automation platform that allows you to extract data from websites efficiently. It supports various tools and integrations, making it a powerful solution for developers and businesses needing to ...